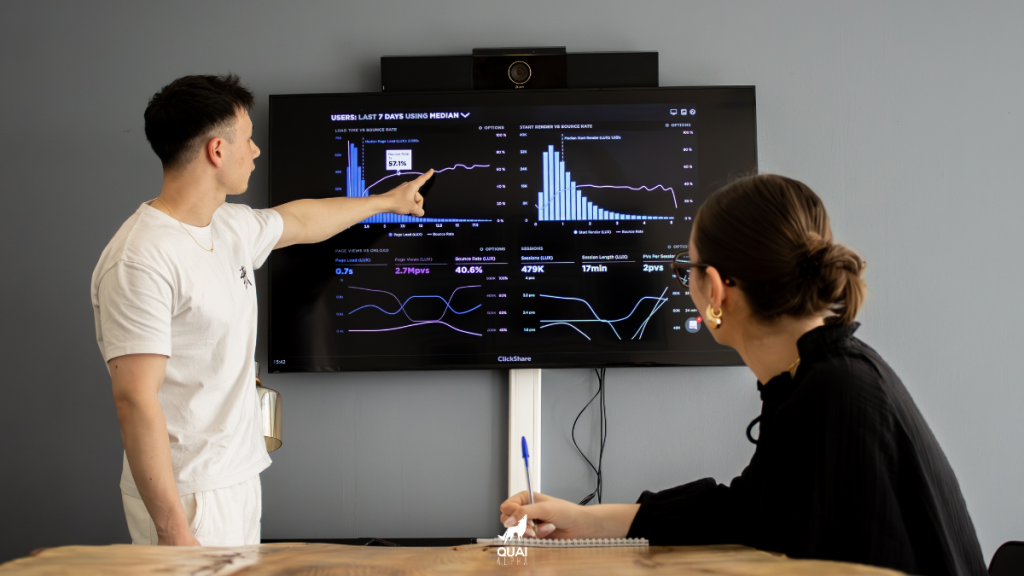
To crawl signifie « Ramper », ou encore « se faufiler ». Le Budget Crawling se réfère donc à la somme, au temps et aux ressources allouées par un tiers (dans ce cas précis Google) pour parcourir une page, des pages, et même le web dans sa quasi-totalité.
Habituellement représenté sous la forme d’une araignée parcourant sa toile (le web donc  ), elle peut être également robotisée puisque l’on parle bien ici de programmes automatisés, d’algorithmes et de robots qui vont parcourir tout internet pour récolter des informations sur les pages qui la composent et en déduire une chose :
), elle peut être également robotisée puisque l’on parle bien ici de programmes automatisés, d’algorithmes et de robots qui vont parcourir tout internet pour récolter des informations sur les pages qui la composent et en déduire une chose :
Est-ce que cette dernière est bien façonnée et optimisée ? Et par conséquent, dois-je la mettre plus en avant dans le moteur de recherche ?
Rassurez-vous, cette approche et cette méthode d’analyse de pages ne vous concernera que si vous avez beaucoup de pages à faire parcourir (plus de 1 000 000 de pages individuelles ou plus de 10 000 mises à jours quotidiennement selon Google), mais la théorie reste néanmoins valable même à plus petite échelle, et ces informations vous serons sans doute utile quant à l’approche du SEO de votre propre site.


Pour aller plus loin :
→ Budget crawl : comment l’optimiser ? chez Semrush
→ Guide sur la gestion du budget d’exploration pour les propriétaires de sites volumineux sur la documentation officielle de Google
→ How to optimize your crawl budget sur le blog de Yoast