

Cette technologie apparue depuis quelques années maintenant fait d'immenses progrès d'année en année. Qu'en est-il aujourd'hui ?
L’intelligence artificielle est un domaine en évolution constante et exponentielle. Elle s’applique à tout un tas de secteurs allant de la linguistique, aux biochimies, en passant par la conduite « automatique » de véhicules.
Mais l’un de ces secteurs dans lequel les avancées sont les plus remarquées, à mesure qu’elles sont dévoilées au grand public, est celui de l’image.
Nous allons faire l’historique de ces technologies, ainsi qu’un état des lieux à l’heure actuelle.

Pas le temps de tout lire ? Clique pour aller directement à la partie qui t’intéresse le plus :
→ Midjourney et Stable Diffusion
Débuts prometteurs
L’intelligence artificielle a d’abord été utilisée et entraînée sur des modèles beaucoup moins complexes que des images. Ces dernières ne sont qu’une suite de « 1 » et de « 0 », interprétés par la machine pour être affiché sous forme d’image pour nous, mais pour un système neural artificiel, cela représente une quantité de données bien trop importante.
C’est pourquoi les débuts de cet apprentissage ont été faits notamment sur du texte, de la reconnaissance de texte, de la traduction, puis enfin de la génération de textes basée sur un précédent. Des entreprises comme Google et son outil de traduction font office de précurseurs dans le domaine.
Le fonctionnement de ce genre de système neural, et autres algorithmes, consistent en un même cheminement d’évolution :
- Apprentissage : le modèle englouti de façon ininterrompue de nombreuses données et modèles afin d’en accumuler le plus d’occurrences possibles et de se créer une base de données (Pour Google Traduction, ce serait comme emmagasiner des dictionnaires, des livres entiers ou même des phrases dans tout un tas de langues.)
- Reconnaissance : le modèle assimile ensuite ces données et les lient les unes avec les autres afin de se les approprier (il classifie les mots, met les phrases dans le bon ordre, lie un mot à sa traduction en une autre langue…)
- Compréhension et modification : le modèle sait maintenant reconnaître ce qu’on lui présente et commence à créer des liens plus intriqués et à donner du sens à tout cela. Maintenant qu’il sait reconnaître de quoi on lui parle, il est également en mesure d’en modifier certains paramètres avant de nous répondre. D’abord inexacte, sa précision augmentera à mesure qu’il échouera et affinera la précision de ses réponses. (Il sait faire des traductions parfois inexactes ou imprécises, mais gagne en fiabilité à mesure qu’il pratique)
- Génération : le modèle maîtrise désormais une large palette d’outils et de connaissances et peut générer une réponse cohérente à une demande initiale, en partant de rien, si ce n’est de la question initiale (principe de génération de textes par IA où l’on donne le début d’un texte et le modèle en comprend le sens et imagine une potentielle suite cohérente)
- (Génération spontanée : le modèle est quasi autonome et ne nécessite plus un « existant » pour commencer à « créer » avec ce qu’il sait. C’est le dernier stade théorique puisqu’à ce jour, aucune intelligence artificielle n’est suffisamment développée pour générer elle même sans s’appuyer sur une demande initiale)

Une de nos premières tentatives pour générer le loup rose emblématique de Quai Alpha de façon « réaliste »
Une fois que l’on a eu mieux compris le principe d’apprentissage de ces nouveaux algorithmes, et que les machines sont devenues de plus en plus performantes (comme le veut la Loi de Moore), il devenait alors possible d’utiliser ces intelligences artificielles sur de l’image, et ce dans cette même logique développée ci-dessus.
Alors, ces modèles ont d’abord permis aux studios d’effets spéciaux de générer des images inexistantes entre deux images déjà existantes après avoir analysé le contenu de ces dernières, c’est ce qu’on appelle l’interpolation. Puis afin de « gommer » certaines parties d’une image, en remplaçant l’indésirable par ce que ce dernier cachait à la base, c’est ce qu’on appelle la rotoscopie. Et au fur et à mesure que ce genre d’algorithmes comprenait comment manipuler une image en analysant son contenu, le comprenant, et en générant par-dessus quelque chose en se basant sur l’existant, il deviendrait de plus en plus aisé de créer une intelligence capable de comprendre des concepts et des idées, et de pouvoir imager ces dernières grâce à sa base de données et son entraînement continu.
C’était d’abord les effets spéciaux professionnels, puis ces technologies se sont démocratisées jusqu’à nos ordinateurs personnels, nos logiciels de retouche, et même directement dans nos téléphones portables lors de la prise de la photo, qui analyse cette dernière en temps réel et peut agir sur certaines zones à la volée.
Nvidia et Canvas
Nvidia est une société connue pour sa conception de processeurs graphiques et de cartes graphiques. Lancée en 1993, elle est aujourd’hui l’une des entreprises leader en matière de technologie de calcul informatique, et se développe de plus en plus du côté de l’intelligence artificielle.
En 2019, Nvidia utilise un cadre de deep learning appelé PyTorch pour développer un projet appelé GauGAN, permettant de générer des paysages à partir de « traits », censés représenter les contours d’un paysage, et en y apposant des étiquettes permettant de définir à l’IA de quelle « chose » il s’agit (herbe, montagne, rivière, ciel…)
À partir de ce modèle proposé, entraîné et amélioré au fil des mois, le logiciel Nvidia Canvas est né et permet aujourd’hui de créer une esquisse qui sera ensuite interprétée par l’IA pour générer un paysage.
Canvas a été le premier logiciel du genre à être mis en avant auprès du grand public, et à être facilement accessible, donnant la possibilité à ce dernier de l’essayer. Une première introduction pour dire : « Cette technologie existe, regardez ce que l’on peut faire avec, et imaginons ce qu’il sera possible de faire dans quelques années… »

Nvidia Canvas transforme des traits et blocs de couleurs en esquisses de paysages.
OpenAI et DALL-E
OpenAI est une association fondée en 2015 par Elon Musk et Sam Altman, devenue entreprise en 2019 afin d’attirer des capitaux et de financer leurs projets.
Spécialisée dans la recherche en intelligence artificielle, elle cherche à s’associer à des startups développant des outils dans des domaines comme la santé, l’écologie ou l’éducation.
La principale IA développée par OpenAI se nomme GPT-2 (pour « Generative Pre-trained Transformer 2 ») et est d’abord un outil entraîné pour générer du texte. Les résultats sont si probants qu’il est presque difficile de faire la différence entre un texte écrit par un humain et généré par ce modèle !
Ces résultats encourageants forcent les chercheurs à garder cet outil encore privé quelque temps, ce dernier ayant un potentiel « trop dangereux » d’utilisations déviantes pour générer de la désinformation ou du spam.
En 2020, sort GPT-3, la version améliorée du modèle, sous forme de bêta privée. Et avec elle, est dévoilé en 2021 un modèle dérivé nommé DALL-E. Mot-valise entre WALL-E (nom du robot du film éponyme des studios d’animation Pixar) et Salvador Dalí, ce modèle fort de 12 milliards de paramètres peut désormais générer des images et illustrer des concepts à partir d’un texte. Il analyse les mots qui composent ce dernier, interprète le sens de la phrase et créé une image censée représenter ce qui est décrit dans le texte, allant du plus terre à terre au plus insolite.
Lorsque les capacités de DALL-E furent dévoilées, les résultats étaient si précis et plausibles pour des images qui « n’existent pas » que cela attira la curiosité de nombreux internautes et chercheurs qui se firent une joie de mettre à l’épreuve cette IA. Depuis 2 ans, l’accès à cet outil est toujours bloqué derrière une demande d’accès à la bêta privée distribuée au compte-goutte, mais des modèles « enfants » disposants de moins de paramètres sont disponible à l’essai sur certains sites, comme Craiyon par exemple.
(Mise à jour du 29/09/22 : DALL-E est désormais en Open Beta et accessible à tous si vous vous inscrivez sur le site officiel. Le modèle reste freemium, et vous aurez accès à 50 crédits (génération d’image) gratuits, puis 15 crédits supplémentaire chaque mois)
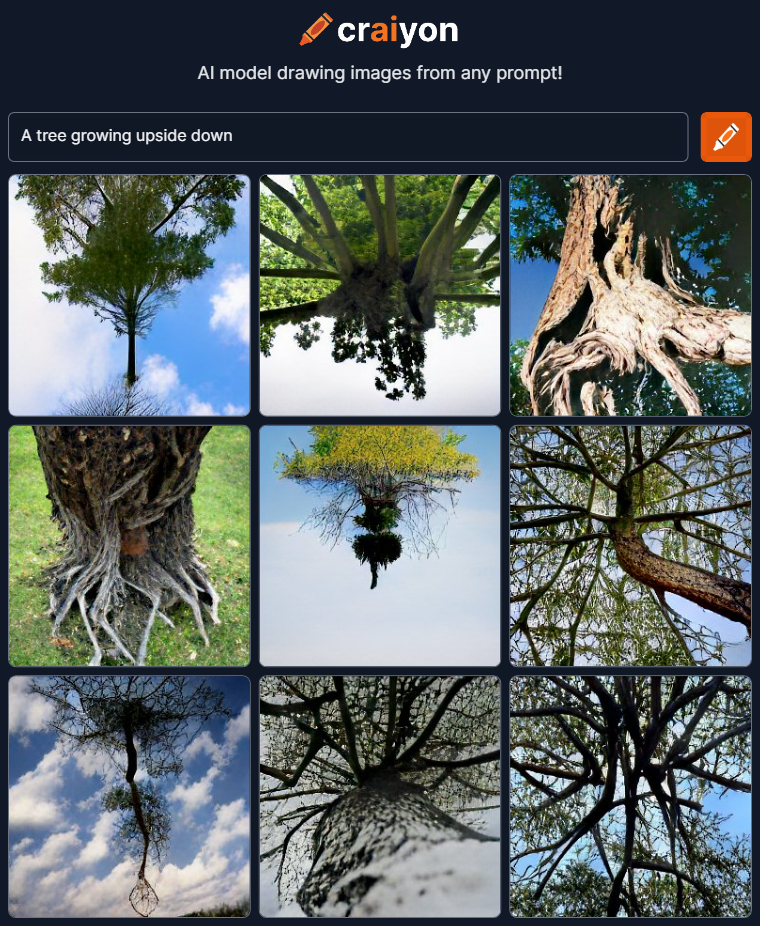
Un exemple généré par Craiyon, le sous-modèle de DALL-E, moins performant et plus abstrait, pour la requête « Un arbre poussant à l’envers ».
Récemment, DALL-E a même dévoilé une nouvelle fonctionnalité pour son outil, l’Outpainting, qui permet, comme son nom l’indique, à l’IA d’analyser le contenu d’une image (et plus particulièrement d’un tableau qui possède un style pictural qui lui est propre) pour ensuite imaginer et générer le décor qui pourrait se trouver au-delà des limites des bords du cadre. Il est même possible de faire des collages entre plusieurs œuvres, reliées par un décor commun imaginé par DALL-E.
Merging art with AI 🖼 ⁇ 🖼 ⁇ 🖼
— Orb Amsterdam (@OrbAmsterdam) September 9, 2022
Using the new Outpainting capability of DALL-E 2, we asked @OpenAI to help us imagine how the landscape could look like between famous impressionist paintings from Van Gogh, Monet, Munch and Hokusai. pic.twitter.com/WSfXnk99Yw
Midjourney et Stable Diffusion
Les années 2020 seront donc peut-être placées sous le signe de l’intelligence artificielle, et de leur nouvelle capacité à générer des images.
Car après le succès de DALL-E et l’exposition de ses œuvres aux yeux de tous, ce sont deux autres modèles issus d’autres sociétés qui sont venues montrer ce qu’elles avaient dans le ventre.
Midjourney d’abord, dévoilée en mars 2022, créée par un laboratoire de recherche du même nom, et au fonctionnement similaire à DALL-E (et non pas basée dessus, ce sont deux algorithmes différents) bien qu’avec des résultats plus « artistiques », là où DALL-E sera plus « réaliste ».
Cette IA utilise un serveur Discord ainsi qu’un bot, permettant à des utilisateurs du monde entier d’interagir avec elle en lui proposant des choses à « dessiner ». Les 25 premières requêtes sont gratuites, et si vous êtes conquis, vous pouvez payer de 10 à 30€ par mois pour débloquer plus de puissance de calcul et plus de requêtes.
Processus de génération d’une mosaïque par Midjourney pour la requête : « Loup rose au milieu d’un champ enneigé, de nuit »
Vient ensuite dans son sillage le dénommé « Stable Diffusion » : lancé en août 2022, ce modèle diffère de DALL-E ou Midjourney de par le fait que son code source est public et se veut être un outil accessible par tous. Publié sous licence Creative ML OpenRAIL-M, le but est d’en faire un outil qui permet un usage commercial ou non, et met l’accent sur une utilisation éthique et responsable de cette technologie.
Cependant, le mode de fonctionnement reste le même, les résultats pourront varier en fonction des moyens alloués pour faire évoluer l’IA, de son volume d’entraînement pour l’améliorer, des résultats qu’elle sera capable de générer… Mais en l’état, ces différents modèles fonctionnent tous de la même manière, ils ne sont juste pas tous gérés par la même entreprise.

Exemple d’images générées par Stable Diffusion © STABILITY AI LTD
Si ces technologies sont encore relativement récentes, les résultats déjà atteignables relèvent presque de l’inimaginable et tendent à laisser penser que les années à venir s’annoncent très intrigantes dans le domaine. Google ont récemment annoncés eux aussi travailler sur une intelligence artificielle similaire nommée Imagen, tandis que TikTok propose sur son application, depuis début août, une fonctionnalité similaire pour générer un arrière-plan personnalisé basé sur une requête.
Les dérives d'une telle technologie
L’une des questions que l’on peut légitimement se poser est : ces IA sont-elles immunisées face à la « bêtise humaine » ? Un outil reste neutre et sera perçu différemment si l’on s’en sert pour être créatif ou bien destructif, et les développeurs qui travaillent sur ces projets l’ont rapidement compris.
Avant d’être ouverts au public, ces modèles ont été entraînés à reconnaître et bannir toute utilisation de mots-clés violents, haineux ou à caractère sexuel, pour éviter de générer du contenu supplémentaire de ce genre. Il semblerait que cette attention toute particulière ait porté ses fruits puisqu’aucun contenu de ce genre n’a semblerait-il fait surface. DALL-E et Midjourney diffèrent cependant dans leur politique à ce sujet puisque là où Midjourney autorise la représentation d’armes, de politique, de maladie ou de personnalité publique (là encore dans un contexte non-violent ou suggestif), DALL-E ne les autorise tout simplement pas.
Bien entendu, ne serait-ce que par curiosité et pour tester les limites de ces protections, des astuces permettent de « tromper » la vigilance de l’algorithme : vous ne pouvez pas demander à voir un cheval mort gisant dans son sang, mais vous pouvez demander à voir un cheval allongé dans un lac rouge. La perception humaine, dont n’est pas (encore) dotée l’IA, se chargera de l’interprétation. Mais les mises à jour régulières des différents algorithmes de compréhension des requêtes semblent être de plus en plus perspicaces pour détecter ces requêtes trop suggestives.
Un autre problème soulevé par cette nouvelle technologie, plus éthique cette fois-ci, est celui de la relation qu’entretient (et va entretenir) cet outil avec les artistes. Le premier problème étant que, pour s’entraîner à « dessiner », l’IA a parcouru des millions d’images disséminées sur Internet, et s’est inspirée du travail de milliers d’artistes, dont certains n’ayant jamais donné leur accord.
Le second problème, est que beaucoup pensent qu’à terme, cette technologie sera capable de remplacer des illustrateurs, ou du moins « voler » une part de travail qui aurait pu être la leur, et ce sans pouvoir rivaliser en termes de ressources nécessaires, de coût et de temps de production. Bien entendu, les résultats et la qualité du travail délivré par ces intelligences artificielles n’atteignent pas un niveau de détail et de finition similaire à un professionnel, mais pour combien de temps encore ?
Là où certains y trouvent un terrain de jeu fantastique, propice à l’inspiration, ainsi qu’un outil sur lequel s’appuyer pour, à partir d’une idée, démarrer d’une première ébauche plutôt que d’une toile blanche ; d’autres y voient une véritable concurrence qui, à terme, sera un outil bien plus compétitif que collaboratif.
Les premières dérives sont même d’ores et déjà constatables : un homme a récemment fait parler de lui en gagnant le premier prix du concours artistique de la Foire du Colorado en soumettant une œuvre réalisée sur Midjourney. Là où l’artiste cherche à prouver qu’il s’agit d’une forme d’expression artistique nouvelle et qui devrait elle aussi avoir une place dans les arts numériques, d’autres artistes eux ne cachent pas leur ressentiment et leur colère.

La toile incriminée, nommée « Théâtre D’opéra Spatial »
Les enjeux et philosophies derrière ce nouveau business
Après avoir été en émoi devant ce que cette IA peut créer, puis en avoir vu les limites et dérives, viennent ensuite des questionnements philosophiques, tels que « l’Art est ce qui fait de nous des humains, donner ce pouvoir à une « machine » n’est-il pas nous destituer d’une part de notre humanité ? » (vous avez 4h)
Il émerge également toutes ces interrogations concernant le modèle économique de ces sociétés et de leurs véritables intentions.
Bien entendu, développer ce genre de technologies est fascinant et permettra à terme de créer d’autres outils encore plus poussés, mais tout cela à un coût, que ce soit en main d’œuvre, en modération, en serveurs et bande passante… Et pour continuer à maintenir et améliorer ces IA, les entreprises et individus doivent y gagner quelque chose, tandis que leur vrai but n’est pas toujours clairement défini.
OpenAI est passé « d’organisation non-lucrative » à « entreprise à but lucratif plafonné » dans l’espoir d’attirer de nouveaux capitaux et de pouvoir rivaliser avec Google, Meta ou d’autres concurrents en matière d’IA.
Midjourney propose quant à lui un modèle de freemium, où les 25 premiers essais sont gratuits pour ensuite passer à une formule d’abonnement payant.
Un tout autre business parallèle s’est également mis en place à la suite de l’explosion du phénomène : le « Prompt Engineering ».
Un « prompt », c’est la requête que vous allez donner à l’IA pour que cette dernière puisse vous générer une image en retour. Cependant, le modèle interprète votre requête en fonction de vos mots-clés certes, mais prend également tout un tas de paramètres : la récurrence de termes, le nombre de termes, la précision, le style utilisé… Il y a tout un langage et une syntaxe à apprendre et à comprendre pour pouvoir « parler correctement » avec l’IA et s’assurer que celle-ci va vous restituer le plus fidèlement ce que vous aviez en tête. Et bien les prompts manufacturer, ce sont eux. Des sites ou des entités, parfois gratuites pour vous aider à comprendre ce langage et à vous familiariser avec l’outil, et parfois mettant au service leur compétence moyennant rétribution.
C’est un peu comme si vous payiez pour les services d’un « conseiller en création artistique générée par IA ». Et ce genre d’entreprise est en train de se démultiplier de façon exponentielle afin de couvrir le plus de domaines possibles, et de s’infiltrer dans cette brèche nouvellement créée pour répondre à une problématique.
Le marketplace « Promptbase » n’est qu’un site parmi tant d’autre qui propose de vendre des requêtes parfaites à soumettre à l’IA
L’évolution de cette technologie est, en tout cas, amenée à soulever de nombreuses discussions, voire à forcer une reconsidération des législations concernant le droit d’auteur. Reste à savoir si ces outils ne resteront que des curiosités artistiques, des compagnons de travail, ou bien une intelligence créative trop compétitive.


