Plus notre technologie évolue et retiens les choses à notre place, plus nous sommes susceptibles de voir notre mémoire régresser.
Cet article est basé sur les travaux des professeurs Betsy Sparrow du Département de Psychologie de l’Université de Colombia, Jenny Liu du Département de Psychologie de l’Université du Wisconsin-Madison et Daniel M. Wegner du Département de Psychologie de l’Université de Hardvard
L’avènement d’Internet, avec ses moteurs de recherche algorithmiques sophistiqués, a rendu l’accès à l’information aussi facile que de lever le doigt. Nous n’avons plus besoin de déployer des efforts coûteux pour trouver les choses que nous voulons. Nous pouvons « googler » un ancien camarade de classe, trouver des articles en ligne, ou rechercher l’acteur qui était sur le bout de notre langue.
Les résultats de quatre études suggèrent que lorsqu’ils sont confrontés à des questions difficiles, les gens sont amenés à penser aux ordinateurs et que lorsqu’ils s’attendent à avoir un accès futur à l’information, ils se souviennent moins des informations elles-mêmes et se souviennent davantage de l’endroit où elles seront accessibles.
L’Internet est devenu une forme primaire de mémoire externe ou de mémoire translative, où les informations sont stockées collectivement en dehors de nous.

Pas le temps de tout lire ? Clique pour aller directement à la partie qui t’intéresse le plus :
Google : un pouvoir sans limite ?
Dans un développement qui aurait semblé extraordinaire il y a à peine une décennie, beaucoup d’entre nous ont un accès constant à l’information. Si nous avons besoin de connaître le score d’un match de football, d’apprendre à effectuer un test statistique compliqué ou simplement de nous rappeler le nom de l’actrice du film classique que nous regardons, il nous suffit de nous tourner vers nos ordinateurs portables, nos tablettes ou nos smartphones pour trouver les réponses immédiatement.
Il est devenu si courant de chercher la réponse à n’importe quelle question au moment où elle se pose que nous pouvons avoir l’impression d’être en manque lorsque nous ne pouvons pas trouver quelque chose immédiatement. Nous sommes rarement hors ligne, sauf par choix, et il est difficile de se rappeler comment nous trouvions des informations avant l’omniprésence de l’internet dans nos vies.
L’internet, avec ses moteurs de recherche tels que Google et ses bases de données telles que IMDB et les informations qui y sont stockées, est devenu une source de mémoire externe à laquelle nous pouvons accéder à tout moment. Stocker des informations en externe n’a rien de particulièrement nouveau, même avant l’avènement des ordinateurs.

Dans toute relation à long terme, dans un environnement de travail en équipe ou dans tout autre groupe permanent, les gens développent généralement une mémoire de groupe ou translative (1), une combinaison de mémoires détenues directement par les individus et de mémoires auxquelles ils peuvent accéder parce qu’ils connaissent quelqu’un qui connaît cette information. À l’instar d’ordinateurs reliés entre eux et capables d’accéder aux mémoires des autres, les personnes en dyades ou en groupes forment des systèmes de mémoire translative (2, 3). La présente étude vise à déterminer si l’accès en ligne à des moteurs de recherche, des bases de données, etc. est devenu une source primaire de mémoire translative en soi.
Nous cherchons à savoir si l’Internet est devenu un système de mémoire externe qui est amorcé par le besoin d’acquérir des informations. Si on nous demande, par exemple, s’il existe des pays dont le drapeau n’a qu’une seule couleur, pensons-nous aux drapeaux ou pensons-nous immédiatement à aller sur Internet pour le découvrir ? Nos recherches ont ensuite permis de vérifier si, une fois l’information obtenue, notre encodage interne s’intensifie pour l’endroit où l’information doit être trouvée plutôt que pour l’information elle-même.
Expérience n°1
Dans l’expérience 1, les participants ont été testés dans deux conditions intra-sujet (4). Les participants ont répondu à des questions faciles ou difficiles de type oui/non en deux blocs. Chaque bloc était suivi d’une tâche de Stroop modifiée (une tâche de coloriage avec des mots présentés en bleu ou en rouge) pour tester les temps de réaction à des termes informatiques et non informatiques appariés (y compris des noms généraux et des noms de marque pour les deux groupes de mots).
Les personnes qui ont été disposées à penser à un certain sujet montrent généralement des temps de réaction (TR) plus lents pour nommer la couleur du mot lorsque le mot lui-même est intéressant et plus accessible, parce que le mot capte l’attention et interfère avec la désignation la plus rapide possible de la couleur. Des tests t appariés à l’intérieur du sujet ont été effectués sur les temps de réaction pour nommer la couleur de mots informatiques et généraux après les blocs de questions faciles et difficiles.
Confirmant l’hypothèse, les mots informatiques étaient plus accessibles [temps de réaction à la dénomination des couleurs moyenne (M) = 712 ms, écart-type = 413 ms] que les mots généraux (M = 591 ms, écart-type = 204 ms) après que les participants avaient été confrontés à une série de questions dont ils ne connaissaient pas les réponses, t(68) = 3,26, P < 0,003, bilatéral.

Il semble que lorsque nous sommes confrontés à une lacune dans nos connaissances, nous sommes enclins à nous tourner vers l’ordinateur pour rectifier la situation. Les termes informatiques ont également interféré un peu plus avec la désignation des couleurs (M = 603 ms, ET = 193 ms) que les termes généraux (M = 559 ms, ET = 182 ms) après des questions faciles, t (68) = 2,98, P < 0,005, ce qui suggère que l’ordinateur peut être amorcé lorsque le concept de connaissance en général est activé.
La comparaison à l’aide d’une analyse de variance à mesures répétées (ANOVA) de moteurs de recherche spécifiques (Google/Yahoo) et de noms de marques de biens de consommation généraux (Target/Nike) a révélé une interaction avec les blocs de questions faciles ou difficiles, F(1,66) = 5,02, P < 0. 03, de sorte que les marques de moteurs de recherche après les questions faciles (M = 638 ms, ET = 260 ms) et les questions difficiles (M = 818 ms, ET = 517 ms) ont créé plus d’interférence que les marques générales après les questions faciles (M = 584 ms, ET = 220 ms) et les questions difficiles (M = 614 ms, ET = 226 ms) (Fig. 1).
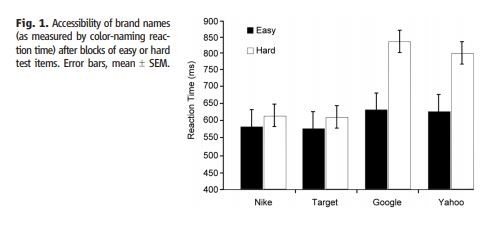
Des tests d’effets simples ont montré que l’interaction était due à une augmentation significative du TR pour les deux termes du moteur de recherche après le bloc de questions difficiles, F(1,66) = 4.44, P < 0.04 (Fig. 1). Bien que le concept de connaissance en général semble susciter des pensées pour les ordinateurs, même lorsque les réponses sont connues, le fait de ne pas connaître la réponse à des questions de connaissance générale suscite le besoin de chercher la réponse, et par conséquent l’interférence de l’ordinateur est particulièrement aiguë.
Expérience n°2
Dans l’expérience 2, ils ont testé les gens pour savoir si ils se souvenaient d’informations auxquelles ils s’attendaient à avoir accès plus tard, comme ils pourraient le faire avec des informations qu’ils pourraient consulter en ligne (4).
Les participants ont été testés dans le cadre d’une expérience inter-sujets 2 par 2 en lisant 40 énoncés mémorables du type de ceux que l’on peut consulter en ligne (à la fois des informations nouvelles, par exemple « L’œil d’une autruche est plus grand que son cerveau », et des informations dont on peut se souvenir de manière générale, mais pas en détail, par exemple « La navette spatiale Columbia s’est désintégrée lors de sa rentrée au-dessus du Texas en février 2003 »). Ils les ont ensuite tapés dans l’ordinateur pour s’assurer de leur attention (et aussi pour fournir un test plus généreux de la mémoire).
La moitié des participants pensait que l’ordinateur sauvegarderait ce qu’ils avaient tapé, l’autre moitié pensait que l’élément serait effacé. En outre, ils ont demandé explicitement à la moitié des participants dans chacune des conditions de sauvegarde et d’effacement d’essayer de se souvenir de l’information. Après la lecture et la frappe, les participants ont noté le plus grand nombre d’affirmations dont ils pouvaient se souvenir.

Une analyse de variance (ANOVA) inter-sujets 2 (sauvegardé ou effacé) par 2 (instructions de mémoire explicites contre aucune) a révélé un effet principal significatif pour la manipulation sauvegardé/effacé, car ceux qui croyaient que l’ordinateur effaçait ce qu’ils tapaient avaient le meilleur souvenir, omnibus F(3, 56) = 2,80, P < 0,05 [Effacer M = 0. 31, ET = 0,04, et Effacer se souvenir M = 0,29, ET = 0,07, comparaisons par paires des conditions effacées non significatives (ns)] par rapport à ceux qui croyaient que l’ordinateur serait leur source de mémoire (Sauvegarder M = 0,22, ET = 0,07 et Sauvegarder se souvenir M = 0,19, ET = 0,09, comparaisons par paires des conditions sauvegardées ns).
Ce résultat correspond à des travaux antérieurs sur l’oubli dirigé, montrant que lorsque les gens ne pensent pas avoir besoin d’une information pour un examen ultérieur, ils ne la rappellent pas au même rythme que lorsqu’ils pensent en avoir besoin (5). Les participants n’ont apparemment pas fait l’effort de se souvenir lorsqu’ils pensaient pouvoir rechercher plus tard les énoncés de futilités qu’ils avaient lus.
Comme les moteurs de recherche sont continuellement à notre disposition, il se peut que nous soyons souvent dans un état où nous ne ressentons pas le besoin d’encoder l’information en interne. Lorsque nous en aurons besoin, nous la consulterons. L’effet principal de l’instruction de se souvenir explicitement ou non n’était pas significatif, ce qui est similaire aux résultats de la littérature sur l’apprentissage concernant l’étude intentionnelle ou fortuite de la matière, qui constate généralement qu’il n’y a pas de différence d’instruction explicite (6, 7).
Expérience n°3
Les participants ont été plus affectés par l’indice que l’information serait ou ne serait pas disponible plus tard, qu’ils pensent ou non qu’ils seront testés sur cette information. Dans l’expérience 3, ils ont testé la mémoire pour savoir où trouver des informations que l’on peut consulter en ligne. Les participants ont de nouveau lu et tapé des éléments de futilités mémorisables, cette fois dans trois conditions sans sujet (4).
Pour un tiers des questions, les participants ont reçu le message « Votre entrée a été enregistrée ». Pour un autre tiers des questions, les participants voyaient « Votre entrée a été sauvegardée dans le dossier X » (où X est l’un des six dossiers nommés FACTS, DATA, INFO, NAMES, ITEMS ou POINTS – des noms génériques interchangeables auxquels les énoncés avaient été préalablement assignés au hasard). Pour le dernier tiers des questions, les participants recevaient le message « Votre entrée a été effacée ».
Les participants s’attendaient à avoir accès à ce qu’ils avaient sauvegardé grâce à un essai supposé « pratique » au cours duquel ils avaient accès aux dossiers de fichiers pendant une tâche de « rappel ». Ainsi, des essais de sauvegarde générique, de sauvegarde dans un dossier spécifique et d’effacement ont été créés pour tous les participants.
Les participants ont ensuite été soumis à une tâche de reconnaissance. Ils ont vu les 30 déclarations, dont la moitié avait été légèrement modifiée (noms ou dates changés). Les participants devaient déterminer si l’énoncé qu’ils voyaient correspondait exactement à ce qu’ils avaient lu, si l’énoncé avait été sauvegardé ou effacé, et enfin, si l’énoncé avait été sauvegardé dans un dossier, dans quel dossier il avait été sauvegardé (les noms des dossiers leur étaient donnés, et ils avaient également « pas de dossier spécifique » et « effacé » comme options de réponse à cette dernière question). Dans l’ensemble, en réponse à la question « Cet énoncé est-il exactement ce que vous avez lu ? », les participants ont reconnu l’exactitude d’une grande partie des énoncés.

Mais pour les énoncés qu’ils croyaient avoir été effacés, les participants avaient la meilleure mémoire (effacer M = 0,93, ET = 0,09, comparaisons par paires avec les deux conditions de sauvegarde P < 0,05) par rapport aux énoncés auxquels les participants croyaient continuer à avoir accès (sauvegardés de manière générique M = 0,88, ET = 0,12, et sauvegardés spécifiquement dans un dossier M = 0,85, ET = 0,12, comparaisons par paires ns), mesures répétées omnibus F (1, 27) = 4,01, P < 0,03. Cependant, le modèle opposé a été trouvé pour la question « Cette déclaration a-t-elle été sauvegardée ou effacée ? ».
Les participants se sont souvenus avec précision de ce qu’ils avaient sauvegardé (sauvegardé de manière générique M = 0,61, ET = 0,21, et sauvegardé dans un dossier M = 0,66, ET = 0,20, comparaisons par paires ns) plus qu’ils ne se sont souvenus avec précision de ce qu’ils avaient effacé (M = 0,51, ET = 0,19, comparaisons par paires avec les deux conditions de sauvegarde, P < 0,04), ANOVA à mesures répétées omnibus F (1, 27) = 5,34, P < 0,03. Ainsi, il semble que le fait de croire que l’on n’aura pas accès à l’information dans le futur renforce la mémoire de l’information elle-même, alors que le fait de croire que l’information a été sauvegardée à l’extérieur renforce la mémoire du fait que l’on pouvait accéder à l’information, du moins en général.
Dans cette tâche de reconnaissance, à la question « Si l’information a été sauvegardée, dans quel dossier a-t-elle été sauvegardée ? », les participants se souviennent davantage que l’information a été effacée (M = 0.54, SD = 0.19, comparaisons par paires avec les deux conditions de sauvegarde, P < 0. 001) que du fait que l’information ait été sauvegardée de manière générique ou du dossier dans lequel elle a été sauvegardée (sauvegarde générique M = 0,30, ET = 0,20, et sauvegarde dans un dossier spécifique M = 0,23, ET = 0,14, comparaisons par paires ns), ANOVA à mesures répétées omnibus F (1,27) = 21,67, P < 0,001.
Ce résultat rappelle l’expérience vécue lorsqu’on se souvient de quelque chose qu’on a lu en ligne et qu’on aimerait revoir ou partager, mais qu’on ne se souvient plus où on l’a vu ou quelles étapes on a suivies pour le trouver, ou même lorsqu’on sait qu’un fichier est enregistré sur son disque dur mais qu’on doit utiliser la fonction de recherche pour le trouver.

Il était important d’inclure le fait que certaines déclarations étaient sauvegardées dans un dossier général pour exclure une augmentation des exigences de mémoire dans les deux conditions de sauvegarde, mais cela ne correspond pas à l’accès continu à l’information que nous connaissons avec la technologie actuelle, en ce sens qu’il n’y a pas de dépôt sans nom d’informations restantes que nous vérifierions après avoir cherché aux endroits évidents.
En outre, la reconnaissance n’est généralement pas la tâche dont nous sommes chargés lorsque nous répondons à une question. Nous devons nous rappeler les informations que nous avons recueillies. L’expérience 4 a été menée pour voir si les gens se souvenaient davantage de l’endroit où trouver une information que de l’information elle-même. Tous les participants s’attendaient à ce que les énoncés du trivia qu’ils lisaient puis tapaient soient enregistrés dans un dossier spécifique portant un nom générique (« FACTS », etc.), comme dans l’expérience précédente, bien que dans ce cas il n’y ait pas eu d’essais pratiques et que les noms et le nombre de dossiers n’a jamais été explicitement portée à l’attention des participants) (4).
Expérience n°4
Les participants ont ensuite été soumis à une tâche de rappel, au cours de laquelle ils disposaient de 10 min pour noter le plus grand nombre d’affirmations dont ils pouvaient se souvenir. Enfin, les participants se voyaient proposer un élément d’identification de l’énoncé qu’ils avaient lu (et qui avait été enregistré), et ils devaient répondre par le nom du dossier dans lequel il avait été enregistré. Par exemple, pour l’affirmation « L’œil de l’autruche est plus gros que son cerveau », la question était la suivante : « Dans quel dossier l’affirmation sur l’autruche a-t-elle été sauvegardée ? ». Les participants devaient taper dans une boîte de dialogue appelée « Items » pour se rappeler correctement ce dossier particulier. Les noms de dossiers n’étaient pas mentionnés à nouveau, après la période de saisie initiale, et les participants n’étaient jamais informés explicitement qu’il existait six noms de dossiers dans lesquels les éléments étaient enregistrés.
Dans l’ensemble, les participants se souvenaient mieux des endroits où les déclarations étaient conservées (M = 0,49, ET = 0,26) que des déclarations elles-mêmes (M = 0,23, ET = 0,14), t(31) = 6,70, P < 0,001 bilatéral. Ces résultats semblent inattendus à première vue, étant donné la nature mémorable des déclarations et la nature non mémorable des noms de dossiers. De plus, ces résultats de rappel sont remarquables en comparaison avec le niveau lamentable de reconnaissance du dossier dans lequel la déclaration a été sauvegardée dans l’expérience 3. Cependant, plusieurs mises en garde s’imposent.
Les participants disposaient d’un indice de mémoire (un mot de l’énoncé du trivia) pour le rappel des dossiers, ce qui n’était pas le cas des énoncés eux-mêmes. Nous n’avons pas été en mesure de contrebalancer les essais sur les faits divers et les dossiers de façon à ce que les dossiers soient aussi nombreux que les énoncés, ce qui serait nécessaire pour contrebalancer les tâches de rappel non guidé et guidé. Cependant, si nous examinons le schéma de ce qui a été mémorisé, les résultats suggèrent que le « lieu » est prioritaire dans la mémoire, l’avantage allant au « lieu » lorsque le « quoi » est oublié.
On pourrait s’attendre à ce que, compte tenu des avantages de la mémorisation assistée, les participants se souviennent davantage du dossier dans lequel les déclarations ont été sauvegardées s’ils y sont incités à la fois par notre question et par le fait qu’ils se souviennent de la déclaration en question. Afin d’examiner cette hypothèse, une analyse de type « si/alors » a été réalisée en attribuant aux participants des scores distincts selon qu’ils (i) se souvenaient à la fois de l’énoncé et du dossier où il était sauvegardé, (ii) se souvenaient de l’énoncé mais pas du dossier, (iii) ne se souvenaient pas de l’énoncé mais du dossier, ou (iv) ne se souvenaient ni de l’énoncé ni du dossier.
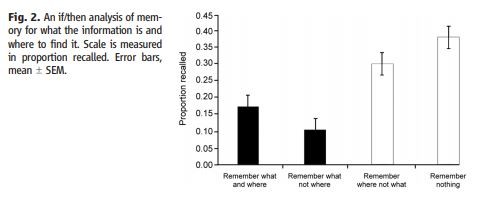
Les participants étaient particulièrement mauvais lorsqu’il s’agissait de se souvenir à la fois de l’énoncé et du dossier (M = 0,17, ET = 0,16) et de se souvenir de l’énoncé mais pas du dossier (M = 0,11, ET = 0,08, comparaison par paire, ns). Ils étaient significativement plus susceptibles de ne se souvenir de rien (M = 0,38, ET = 0,24), mais étonnamment tout aussi susceptibles de se souvenir du dossier, lorsqu’ils ne se souvenaient pas de la déclaration (M = 0,30, ET = 0,16, comparaison par paires, ns), mesures répétées ANOVA omnibus F (1, 31) = 11,57, P < 0,003 (Fig. 2). Il semblerait, d’après ce schéma, que les gens ne se souviennent pas du « où » lorsqu’ils savent « quoi », mais qu’ils se souviennent de l’endroit où trouver l’information lorsqu’ils ne s’en souviennent pas.
Il s’agit d’une preuve préliminaire que lorsque les gens s’attendent à ce que l’information reste disponible en permanence (comme c’est le cas avec l’accès à Internet), ils sont plus susceptibles de se souvenir de l’endroit où la trouver que des détails de l’article. On pourrait dire qu’il s’agit là d’une utilisation adaptative de la mémoire, qui consiste à considérer l’ordinateur et les moteurs de recherche en ligne comme un système de mémoire externe auquel on peut accéder à volonté.
Le fait de se fier à nos ordinateurs et aux informations stockées sur Internet pour se souvenir dépend de plusieurs des mêmes processus de mémoire translative qui sous-tendent le partage d’informations sociales en général. Ces études suggèrent que les gens partagent facilement des informations parce qu’ils pensent rapidement aux ordinateurs lorsqu’ils constatent qu’ils ont besoin de connaissances (expérience 1).
La forme sociale du stockage de l’information est également reflétée dans les résultats selon lesquels les gens oublient les éléments qu’ils pensent être disponibles à l’extérieur et se souviennent des éléments qu’ils pensent ne pas être disponibles (expériences 2 et 3). La mémoire translative est également évidente lorsque les personnes semblent plus à même de se souvenir de l’endroit où un objet a été stocké que de l’identité de l’objet lui-même (expérience 4). Ces résultats suggèrent que les processus de la mémoire humaine s’adaptent à l’avènement des nouvelles technologies informatiques et de communication.
De la même manière que nous apprenons, par le biais de la mémoire translative, qui sait quoi dans nos familles et nos bureaux, nous apprenons ce que l’ordinateur « sait » et quand nous devons faire attention à l’endroit où nous avons stocké des informations dans nos mémoires informatisées. Nous devenons symbiotiques avec nos outils informatiques (8), devenant des systèmes interconnectés qui se souviennent moins en connaissant l’information qu’en sachant où elle peut être trouvée. Cela nous donne l’avantage d’avoir accès à une vaste gamme d’informations, même si les inconvénients d’être constamment « connectés » font encore l’objet de débats (9).
Mais ce n’est peut-être plus que de la nostalgie que de souhaiter que nous soyons moins dépendants de nos gadgets. Nous sommes devenus dépendants d’eux au même degré que nous sommes dépendants de toutes les connaissances que nous acquérons de nos amis et de nos collègues de travail – et que nous perdons s’ils sont déconnectés. La perte de notre connexion Internet s’apparente de plus en plus à la perte d’un ami. Nous devons rester branchés pour savoir ce que Google sait.
Références et notes
- D. M. Wegner, dans les Théories du comportement du groupe, B. Mullen, G. R. Goethals, Eds. (Springer-Verlag, New York, 1986), pp. 185–208.
- D. M. Wegner, Soc. Cogn. 13, 319 (1995).
- V. Peltokorpi, Rev. Gen. Psychol. 12, 378 (2008).
- De nombreuses ressources et méthodes sont disponibles sur Science Online
- R. A. Bjork, dans les processus de codage dans la mémoire humaine, A.W. Melton, E. Martin, Eds. (Winston, Washington, DC, 1972), pp. 217–235.
- F. I. Craik, E. Tulving, J. Exp. Psychol. Gen. 104, 268 (1975).
- T. S. Hyde, J. J. Jenkins, J. Exp. Psychol. 82, 472 (1969).
- A. Clark, Natural-Born Cyborgs: Esprits, Technologies, et le futur de l’intelligence humaine (Oxford Univ. Press, New York, 2003).
- N. Carr, Atlantic 302, 56 (2008)